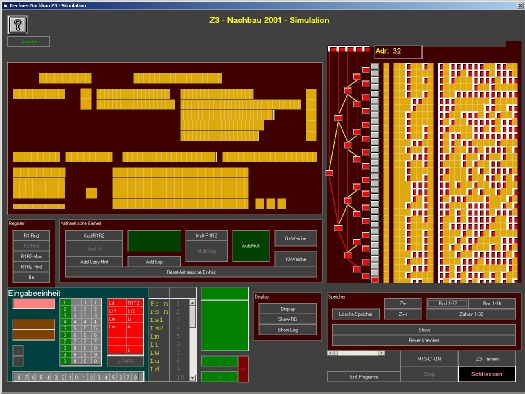
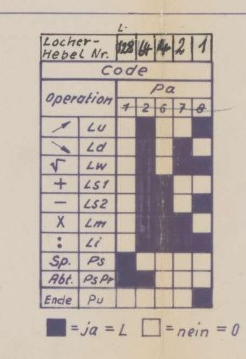
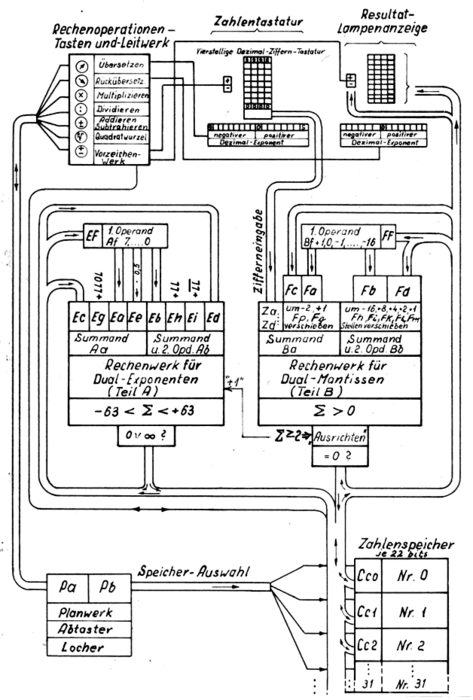
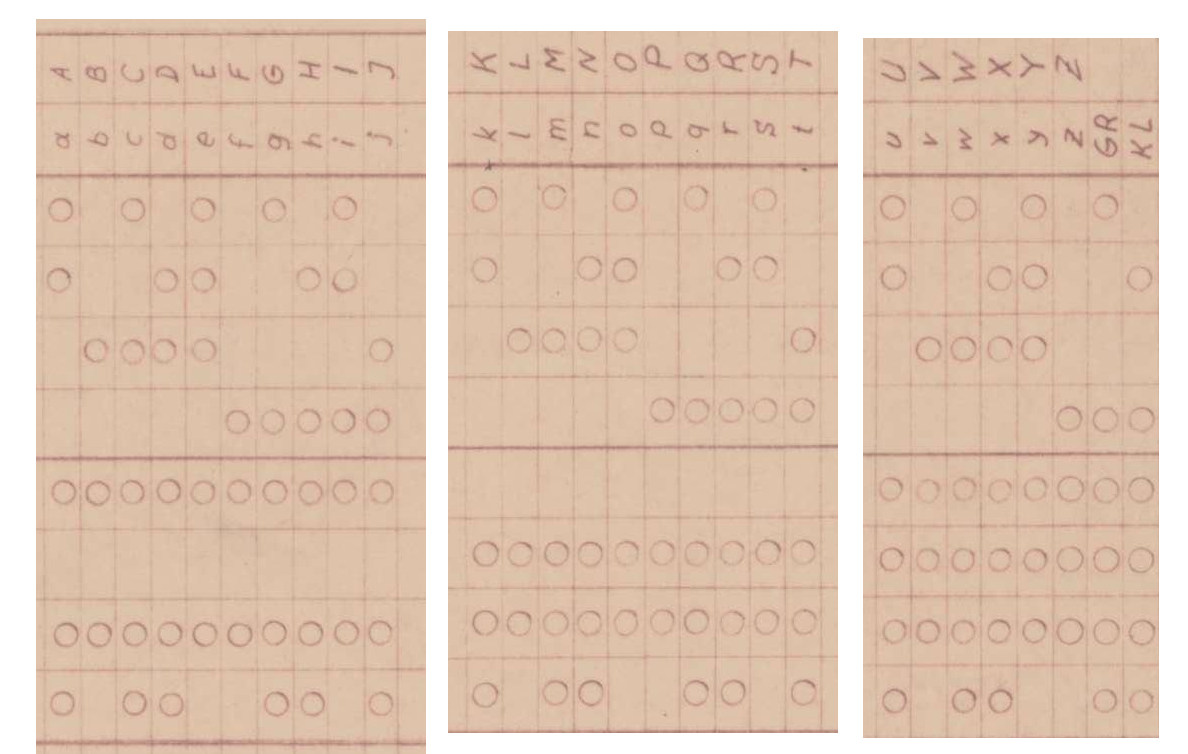
That is a fair assumption and if I were to throw binary code on a coin, I’d definitely embed some clever message, not too obfuscated to decypher.
Even with the assumption that there are missing bits, the total would be 220, again, not a number divisible with 8. That’s not to say it MUST be divisible with 8, but it is rather uncommon for uncompressed data to end with an incomplete byte.
But, let’s try to have another angle at this. Supposing that the text would be uncompressed and it would end-up at some point (regardless of the number of bits) to represent characters in a successive pattern (i.e. A = x, B = x+1, C = x+2 and so on), we should be able to observe that pattern in regular text because, as Shakira would say: “Bits don’t lie”.
So, I have taken a sample english text, converted it to binary and looked for pattern 110, for instance. And here is that pattern with differend bit paddings:

You will see here that the 110 pattern tends to align when the padding reaches 8, and forms a nice vertical pattern in most cases.
Now, looking at our binary data searching for the same pattern (starting with a minimum padding of 5, since the alphabet requires at least 26 characters which need at least 5 bits of data):

Now, you see that the same pattern is all over the place, doesn’t align nicely as the text before did.
While this is by no means an exhaustive analysis of the data, by this alone, I am pretty sure that if the binary sequence contains textual information, it is encoded or compressed differently.
Also, given the work of Mr. Zuse, I’d expect that the binary code contains actual machine instructions instead of characters, but this too is a speculation.