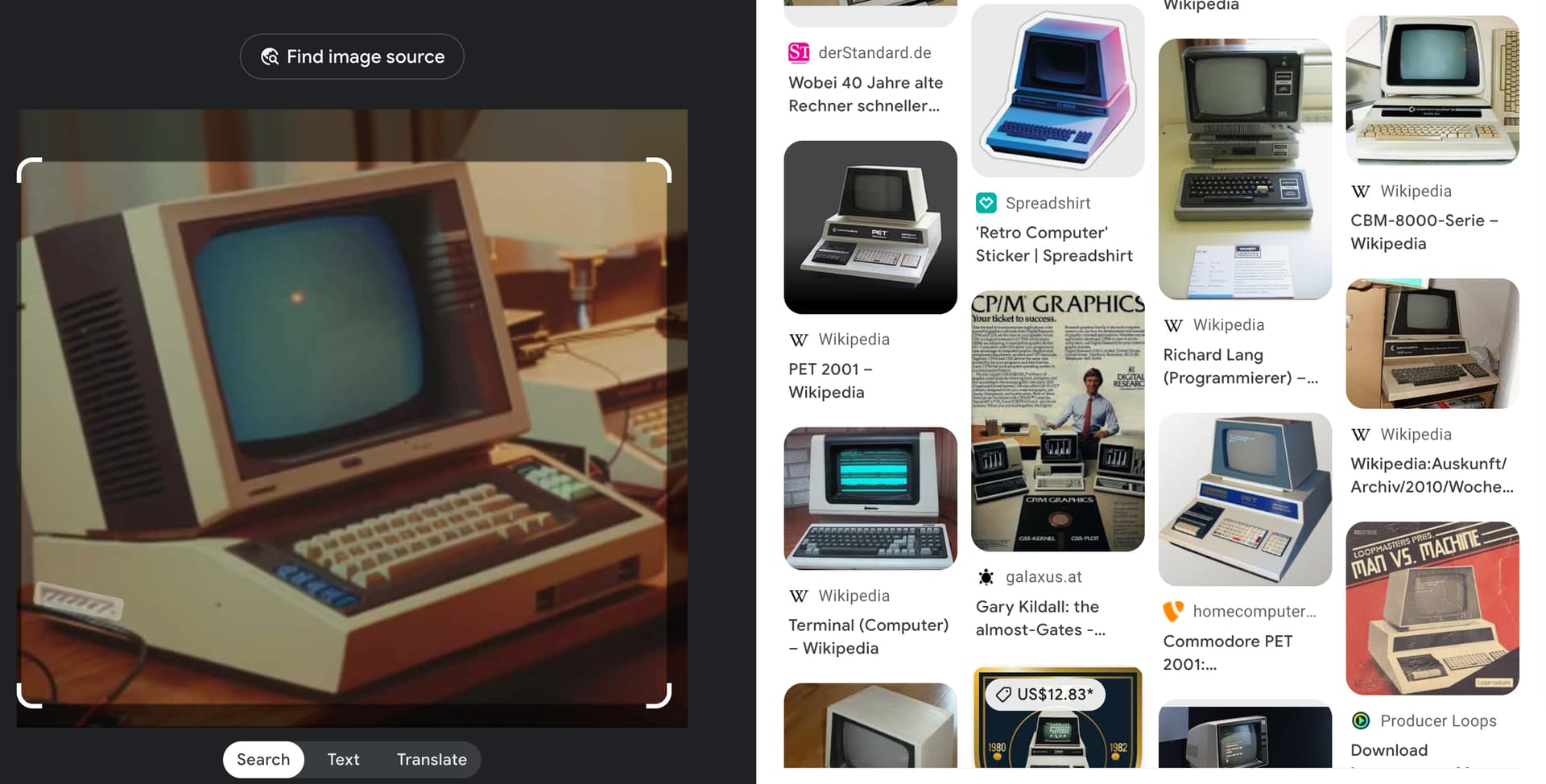
Back over, at http://retrocomputing.stackexchange.com, there was a post asking for help in identifying a computer from an image (deleted, since). This is the image in question:

While rather convincing at first glance, it’s obviously an A.I. generated image.
Here, I’ve marked a few areas, where things either don’t make sense or are off (like “mutilated” keys, suitable for AI fingers only, or perspective):

There may be also some aesthetic hints, like that monitor glow being just a bit too nice.
However, this made me think: in a year or two, there won’t be such dead giveaways that an image was generated, as these algorithms are constantly improving (and these offending details are an annoyance to the respective developers). Meaning, these images will either send well-meaning enthusiast on a meaningless scavenger hunt, or any such requests will be routinely dismissed with a “well, that’s A.I.”, even if it were a not that well known but real historic artifact, maybe even of some relevance. (Thus, eventually restricting the field to just a handfull or so of well known computers. “I do know a C64C and a C128, but that C65 is obviously fake, because I don’t know it.”)
How are we going to proceed? How are we tackling this problem, especially in the retro-computing community, where there are certainly some obscure artifacts, which are still to be explored. (We even had a few “do you know that machine” puzzles, here.)
On the other hand, these algorithms are tuned for generating interesting images with typical traits, which may also generate interest in what they are depicting, whenever they pop up, an interest, which is to be frustrated, as their origin is eventually revealed. (The very nature of historic and often ephemeral photos, which are generally poor in image quality, only aggravates the problem, by hiding any dead giveaways in an overall lack of color precision, lack of dynamic range or resolution.)
Are we going to build an image database of machines that actually existed, so that we can verify any images against this? Is there any interest for such an effort? In any case, if we come up with a viable and practical idea, we should start soon, before the algorithms become too good for those images giving away their very nature immediately.