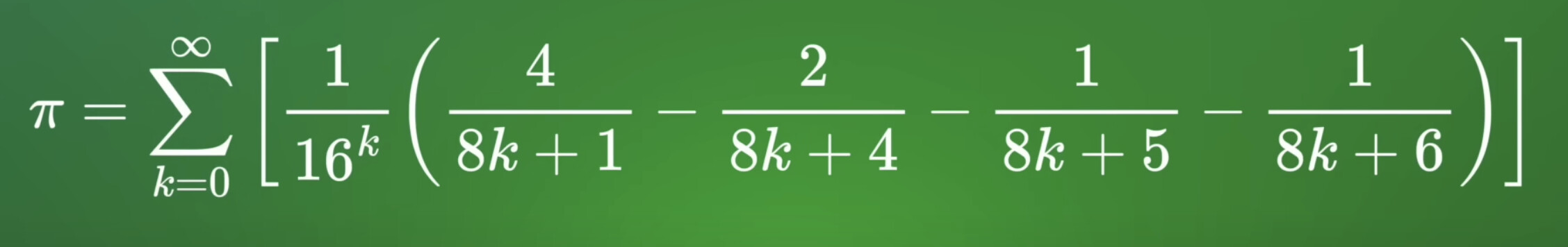The BBP formula gives rise to a spigot algorithm for computing the nth base-16 (hexadecimal) digit of π (and therefore also the 4nth binary digit of π) without computing the preceding digits. This does not compute the n th decimal digit of π (i.e., in base 10).[3] But another formula discovered by Plouffe in 2022 allows extracting the n th digit of π in decimal.[4]
It computes 32 digits in about 37 minutes and can theoretically compute 4096 digits in about 1.3 years.
Wonderful! (Worth noting, as it’s just a little disappointing, the necessary memory for the calculation is implemented by a Raspberry Pi. It would be nice to think there’s some suitably old-school way of doing that, preferably mechanical or electromechanical. It would be handy if the memory is just a few registers which are accessed sequentially.)
Edit: musing on storage-efficient variants of pi spigots, I found an EDSAC version on Rosetta code.
this program implements the spigot algorithm of Rabinowitz and Wagon. The code takes up 192 EDSAC locations, leaving 832 for storage, which is enough for 252 correct digits of pi.
Edit: nice source of historical pi records, the earlier ones being very much on-topic here:
I’d quite like to understand a bit more about the multiply-by-ten thing. I think I can see that the basic formula is producing hex digits (or a binary result, being the same thing)…
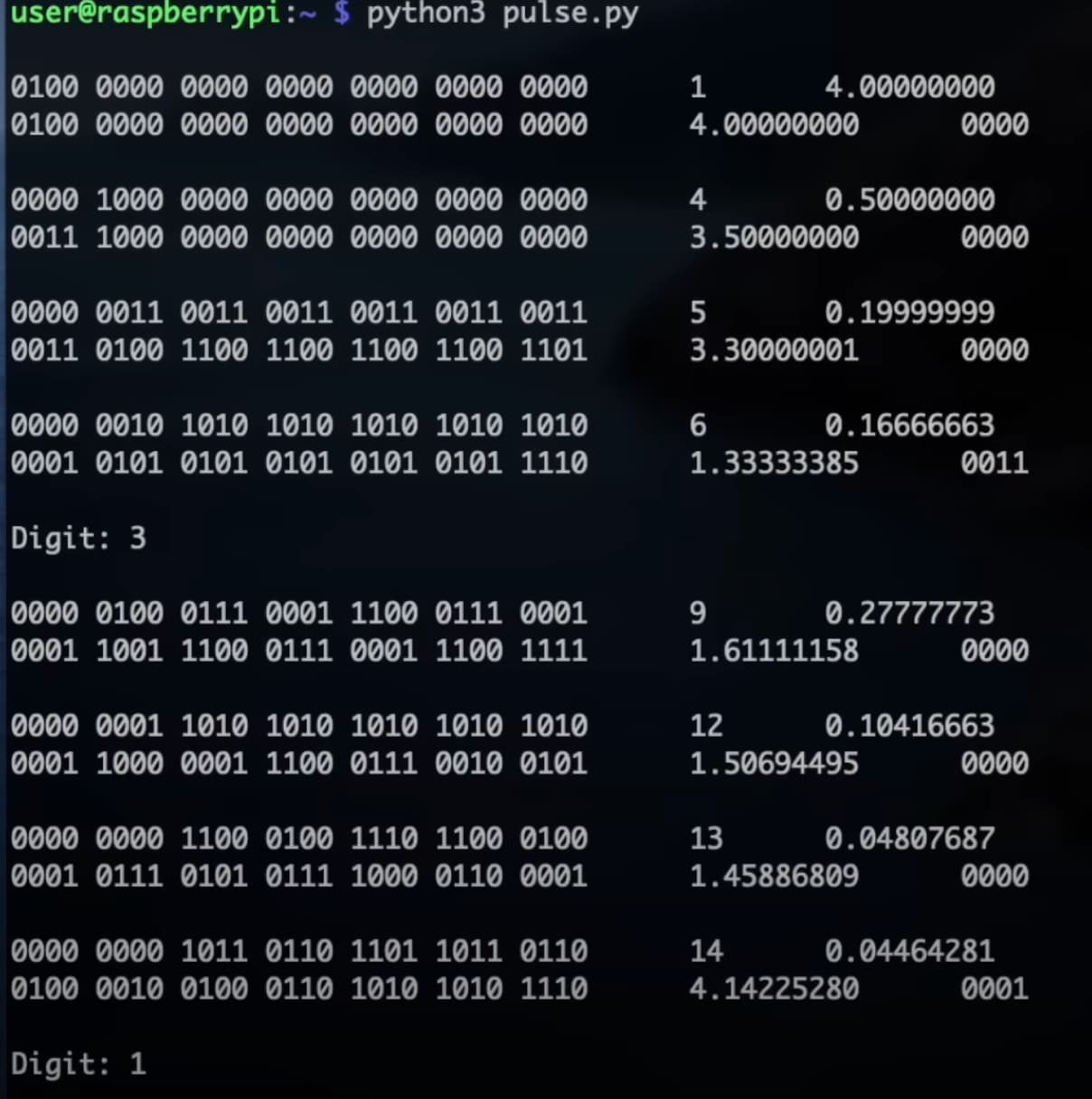
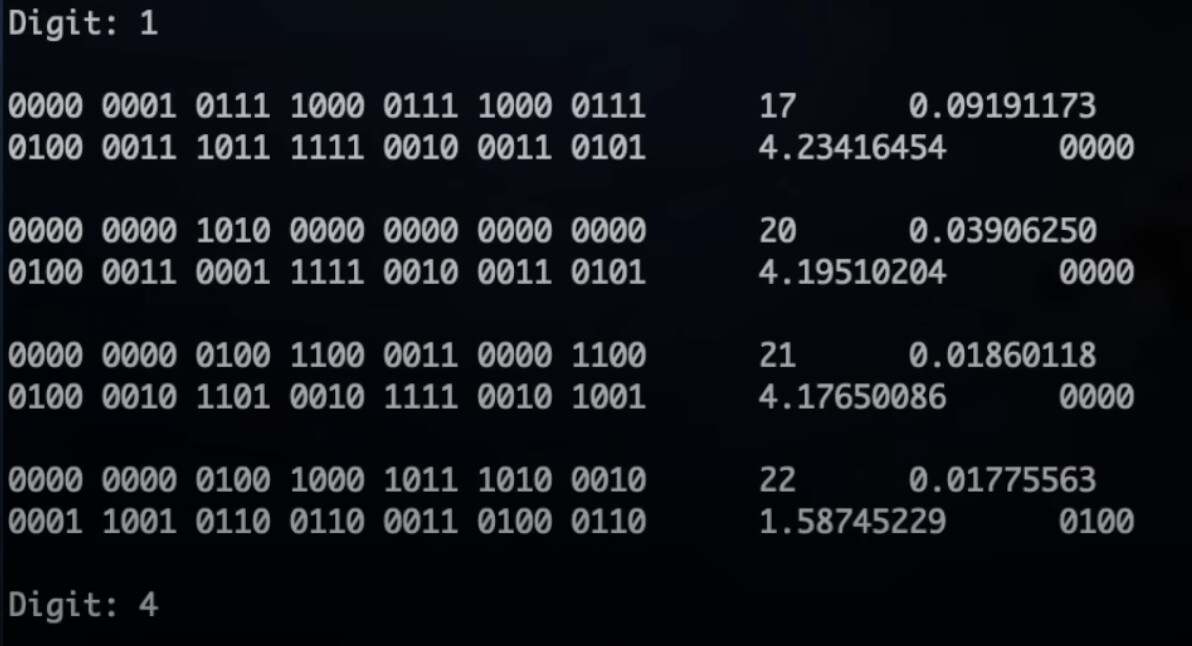
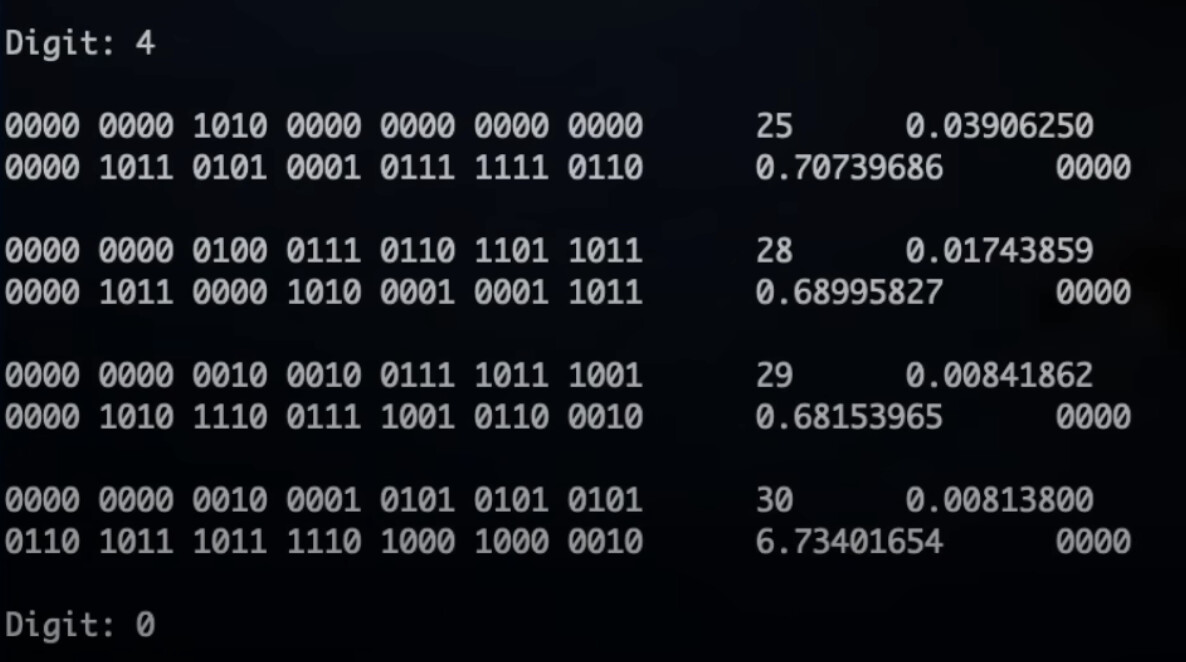
…and I can see that one can convert a binary (or hex!) representation into decimal by repeated multiplication by 10 and taking the integer part. But for a spigot, there’s presumably a hex accumulator which needs to accumulate new terms, and which gradually gains more correctness, but you can’t just multiply it by ten, because you’d need also to multiply all subsequent terms by ten as well. Any thoughts on how the accumulator might be being managed? Screenshots from the python simulator might possibly help, as seen in the video:
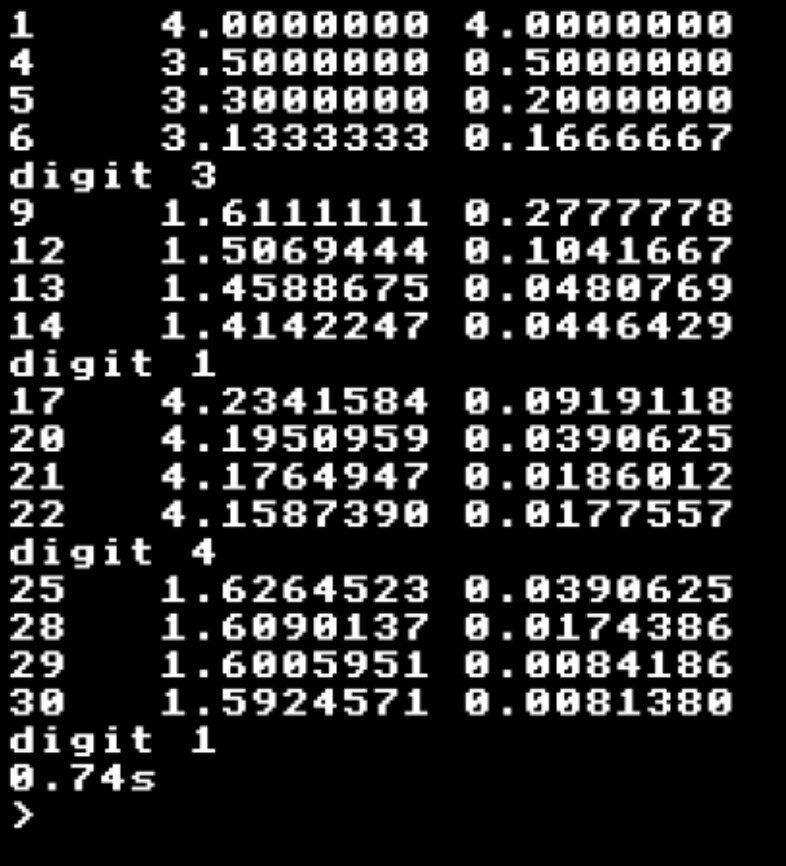
Ah - got it! We must multiply the accumulator by 10 to get the next decimal digit, and to keep the terms lined up we can also multiply up the numerator by 10. Instead of 4, 2, 1, 1 the numerators become 40, 20, 10, 10 and so on. I think. Here’s a BBC Basic program which shows the idea working, anyway.
T=TIME
M=1:N=1:S=0
FOR K%=0 TO 24 STEP 8
J%=K%+1:T=4*N/J%/M:S=S+T:PROCp
J%=K%+4:T=2*N/J%/M:S=S-T:PROCp
J%=K%+5:T=1*N/J%/M:S=S-T:PROCp
J%=K%+6:T=1*N/J%/M:S=S-T:PROCp
PRINT "digit ";INTS:S=S-INTS
S=S*10
N=N*10
M=M*16
NEXT
PRINT (TIME-T)/100"s"
END
DEF PROCp
@%=&304
PRINT ;J%," ";
@%=&20706
PRINT ;S;" ";
@%=&20706
PRINT ;T
@%=&304
ENDPROC
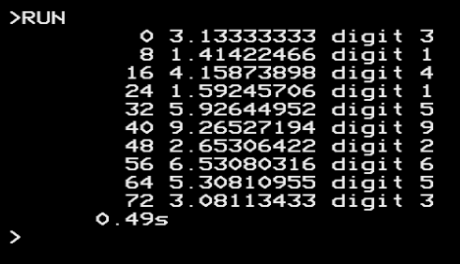
Just a quick addendum, having satisfied myself that I had a glimmer of an understanding of the approach used in the relay machine, I could re-write the Basic more simply like this, still giving one digit at a time:
REM BBP pi calculation like youtu.be/SPTzzSuBFlc
T=TIME
S=0:K=1
FOR I%=0 TO 72 STEP 8
S=S+K*(4/(I%+1)-2/(I%+4)-1/(I%+5)-1/(I%+6))
PRINT I%," ";S;" digit ";INTS
S=S-INTS
S=S*10:K=K*10/16
NEXT
PRINT (TIME-T)/100"s"
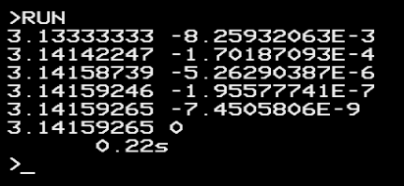
And then, if we don’t need it digit by digit, we can get the result even faster, by getting full value from each hex digit, like this:
REM BBP pi calculation like youtu.be/SPTzzSuBFlc
T=TIME
S=0:K=1
FOR N%=0 TO 5
I%=8*N%
S=S+K*(4/(I%+1)-2/(I%+4)-1/(I%+5)-1/(I%+6))
PRINT S" ";S-PI
K=K/16
NEXT
PRINT (TIME-T)/100"s"