I thought I’ld let you know what I’m currently working on - my notes (written initially for my own benefit but starting to turn into a web page for whatever the final code may be) is at Custom OCR for mono-spaced line-printer listings with the WIP code in the directories at that level. It’s too long a post to repeat here, and a shorter version wouldn’t cover everything I want to mention, so I’ll ask you to read the document at my web site. This is primarily for recovering a bunch of listings that the Edinburgh Computer History project has, but I’ll do my best to turn it into something that anyone can use.
7 Likes
What an ambitious project! My limited experience with off-the-shelf OCR products has been … well, it’s been close to useless. We still use manual keying for almost everything.
Can one assume the source for the printer listings is not avaliable, or do we have politics
or legal involved?
Far from it! Everything I have and do is on gtoal.com, somewhere. May take a little creative searching to find anything specific, but you can always ask me to find something. The software is at that URL and many scans can be found at Edinburgh Computer History Project - documentation scans and elsewhere.
(Or did you mean the original files that were printed out? Those are lost. We only resort to scanning listings for files that we can’t locate originals of)
Exactly, and having done that rekeying a few times I’m reluctant to do it again!
1 Like
Very interesting. I haven’t been logged in for quite some time, I logged in just to state my interest. Lots of old listings around here, I wondered what I could do.
That is a very interesting project!
I think your project would benefit from repeated scans. The way I’d do it would be to set up a bench camera (basically a webcam strung up above a plate with some controlled liberty to slightly move x/y).
You would place your subject on the below plate, scan it, move the camera, scan it again and maybe do that 10 passes. On each pass, you’d make the determination of what’s on that grid, which, given the hypothesis, is always a grid of characters. By repeating the process you make statistical determinations of what specific characters are at position (example: 10, 25). Is it an S or a 5?
I would not limit to projectual movement of the image captor, I would also work on the contrast of the image and repeat that scan on those deltas of contrast.
At the end of the day, you’d see what identified character takes most statistical presence and assume that’s it.
Then, in the “learning” stage, you’d visually compare and try to refine your recognition process. Maybe you need to implement several parallel recognition functions. I expect that the printers would have had some biases of toner impregnation depending on make, paper type and so on, which would make the glyphs pose some artifacts making them slightly offset for the same character on multiple instances or even across printers.
I’m rather surpried you mention the process is slow. I’d expect such analysis done on a modern computer takes the time to:
- take pictures (that’s if you don’t feed the images directly);
- run some computing algorythm(s) on a bitmap, maybe determining the black density over a grid you apply on a character’s determined space (?).
As a programmer I feel that the second point should be blazing fast, but maybe your recognition algorythm has some complexities I cannot immediately think of. I’d love to hear more and maybe offer some help, if at all possible.
Anyhow, great project, good luck with it!!
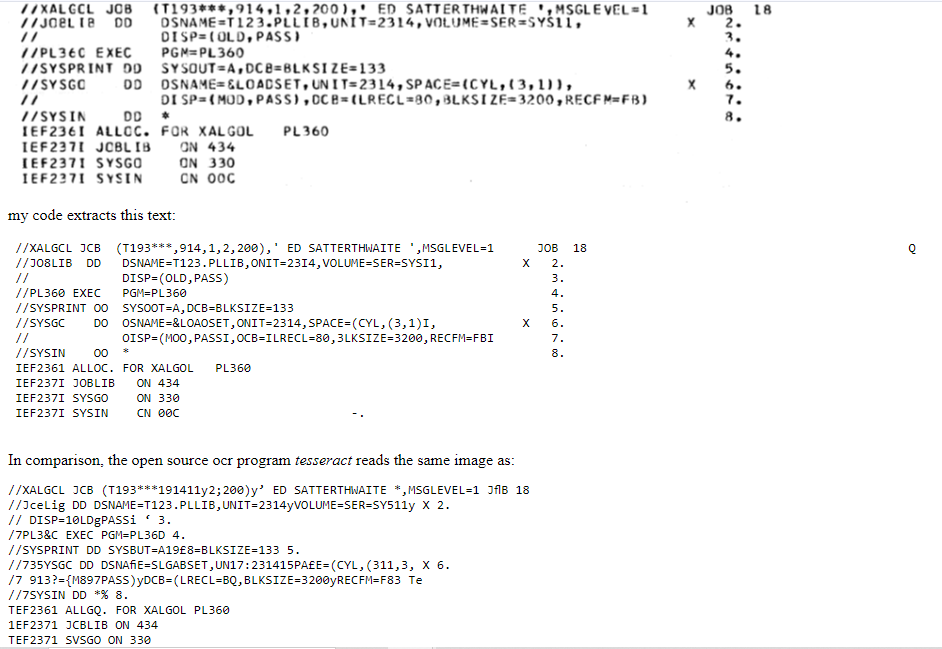
Appreciate the thoughts, but unfortunately repeated scans are not an option for most of the listings I’ll be working with; they were scanned once maybe 20 to 30 years ago and most likely at 300 dpi 1-bit level ![]() This project is an attempt to do as best as I can manage from poor data. By the way I just updated my web page with a small worked example.
This project is an attempt to do as best as I can manage from poor data. By the way I just updated my web page with a small worked example.
Also very few of these listings will be from dot matrix printers and none from lasers. Most are from band printers and a few will be from flexiwriters and diabolos (which are more like typewriters).
The basic algorithm is to take an unknown glyph, and then compare it against a known glyph at multiple positions, and do so for every known glyph (i.e. about 100 known glyphs and order of magnitude, 500 different offsets, though that is scanning resolution dependent) - so maybe 50,000 comparisons of a roughly 50x50 bitmap, but the comparisons are not a cheap logical operation either. So that’s roughly 50000 * 2500 = 125000000 complex comparison operations per letter. Hence why it’s slow. There will be some opportunities for optimisation later, but I need to tune the recognition with the full strength of brute force! ![]() Once the recognition is as accurate as it is possible to be given the inputs, then I’ll work on speeding it up.
Once the recognition is as accurate as it is possible to be given the inputs, then I’ll work on speeding it up.
The advantage we get from these old listings is that we know they map to a grid, so initial segmentation is far easier than it would be with proportionally spaced text…
PS the source code is under that same directory https://gtoal.com/src/OCR/ - segmenter/ extracts the individual glyphs and recogniser/ recognises them. It’ll be a day or two behind what I’m working on as I’ll only be updating at at various checkpoints when some new feature is testd and works. I may upload some single test page data but not any whole documents as the working data for the 300 page doc I’m working on is about 2Tb. ![]()
3 Likes
Tor, the primary objective in recovering old software is to get a good scan (and preferably share it online or at least make sure others have copies). When we started the Edinburgh Computer History Project we asked that all new scans would be made in colour or grey scale (not monochrome) and at 600dpi or larger (pref. 1200dpi) on the assumption that although OCR at the time (this was about 30 years ago) was crap, it would be better in the future. Well, this is the future and frankly OCR has barely improved, hence this project… I can’t do anything to improve the general state of OCR but I might be able to improve this very small subset specific to old lineprinter listings. If/when I do, it would be great if you had scanned those printouts you mentioned. Flatbed scanner with the lid down. and if the pages are too wide to fit, scan twice with as much overlap as possible to help join the images back together automatically.
1 Like
TBF, OCR has improved incredibly since then: it’s that the expected output goal of OCR has changed.
What you are needing is perfect transcription: because it’s source code, no amount of spell checking will help you. You don’t have staff to throw at the problem of proof correction. Speed doesn’t matter to you: only accuracy.
OCR now is blazingly fast, but that’s at a cost of less than perfect accuracy. OCR’s now a general “let’s get the rough idea of what’s on these scanned papers” tool that helps people index and collate documents, not transcribe them perfectly.
Modern “OCR and translate” is effectively magic: give Google Translate a scanned datasheet in Mandarin, and it’ll give you something to work from in rough but serviceable English. I remember being at a symposium in Cambridge roughly 25 years ago where Xerox demoed a smart photocopier that attempted to print translations of words you highlighted in the margin. It had a tiny vocabulary, and even in a fairly closely-controlled demo environment, it wasn’t always perfect. (Olivetti Research were also there - then recently split from Acorn - showing off their video voicemail indexing system. I think that was too far into the future for most people to follow.)
I’d be interested to see what your approach does with the original MIL publications of Hershey’s font data. The original Usenet Hershey project made some fairly obvious transcription errors
is it monospaced text? I can add a page of it to my test corpus if you want - point me at the scans. I wasn’t aware that the Hershey fonts still contained errors.
Paper is always a secondary medium for recovering software. Why is the source missing
or distroyed as being worthless? If the information is owned by the University, perhaps the
laws need to be changed. I pay to to learn stuff, yet anything I create you own as IP.?
If it was created back in the 70’s why can’t it be recreated again?
Confused person who took courses in Electronics rather than Computer Science,
Understood. Here’s a thought. Instead of comparing each newly discovered glyph, maybe compare it with all other already discovered glyphs. At this first pass, the objective would be to group possibly identical glyphs together while also keeping each instance of a glyph belonging to a group. This could help to also identify ambiguities (i.e. glyphs at a specific grid place which land in more than one group group).
Then you would iterate through all groups and for each of them check each glyph trying to determine what it is.
If a reasonable percentage of that yields the same character you could assume that’s your symbol for that specific group.
This also gives you (hopefully) the information that all other groups will not be this symbol you just found, simplifying a bit the rest of the process.
What I believe is useful with this approach is that you might have a more reliable match chance, since you would first match the glyphs you discover on the same document (or set of documents in the same batch). For glyphs which don’t land in multiple groups, you should be able to determine with absolute certainty what they are.
Then, you have multiple candidates that can land you a successful match once you start on each group.
Offcourse, this is also a discovery suggestion, one would need to go back-and-forth with this approach, tweaking some aspects of it depending on preliminary results.
I’ll probably try and give it a shot. Do you think you can also attach some real sample pages to your website? I’ll try to find some time to get something going, at least to satisfy my curiosity. ![]()
What do you do with line printers that print one and and the letter I as the same glyph
or zero and the letter O?
Punched holes can also be nasty for listings.
Do you need to scan the whole document perfect?
A assmbler listing might have the address and order code as hex numbers,
and the general text. Since in most cases only numeric data is needed
that only needs to be 100% correct and you only have 0-9A-F to pick from.
PS: I forgot punched cards don’t have lower case.
Indeed, very good points. For similar glyphs such as O, o, 0 or even D, I’d rely more on fine tuning the recognition process, but for systems that use the same glyph for multiple symbols I think it is reasonable to introduce an ‘interpreter’ pass (which can also heavily help with the previous point).
An interpreter would have knowledge of all keywords or rules of composition that are found in the text, per specific language.
Depending on how many languages we’re talking about, this can quickly escalate. ![]()
… And even that will probably not work for situations where a user string is provided, such as: PRINT “Hello world”
But at least it will get you closer.
That’s somewhat similar to my original proposal, which was to use k-means clustering to group glyphs together, and then create a master glyph by averaging them. Which I may still do in some aspect, but in this prototype stage I’m just working from hand-picked good examples of each character, with a small amount of hand tweaking (in nchar.h). Keeping multiple examples of each character to compare against isn’t an option as the speed degrades linearly with each char in the database. (although there may be tricks to optimise that later.)
One other thing to consider is parallelising. For example I must have something on the order of 300 - 400 cores available if I could be bothered to hook up all the Pis and Pi Zeroes I have here. Just about every single aspect of this problem lies in the ‘embarrassingly parallel’ domain.
There’s little advantage in ordering tests to get an earlier result as you have to compare against all glyphs before you can conclude the result. You can’t say “this looks good” and quit because a better match might come along later that you would have missed. At least in a general system. Once you start assuming a specific font, there are tweaks you can make in that area, but I’m trying to avoid font-specific tweaks in the early stages of development.
2 Likes
I’ve uploaded the first page of the test doc I’m using, to https://gtoal.com/src/OCR/testdata/ALGOL-W/
If you have a spare computer and lots of free time, you can also regenerate the whole document and WIP by running https://gtoal.com/src/OCR/segmenter/segment.sh
2 Likes
I looked through some of the listings I have… the most interesting ones are on wide listing paper (i.e. somewhat difficult for me to scan, but it can be done), but they’re also suffering from faded text. Readable, but faded. These are listings of about half of an operating system.
Ah, if you already mentioned that, I missed it. Sorry for repeating.
I think your approach is excellent, you are going about this the engineering way, starting from the very graspable/controllable and moving on to whatever leads next. My approach is a bit different in the sense that I early explore dramatically different conceptual approaches. For instance, your latest messages encourage me to think of vectorial interpretations of the source imagery. Can I possibly detect lines, curves and paste them together into something I can define as a uniquely recognizable symbol? In such a sense, I would not be restricted to source sample images to compare against, I would consider what letter “A” is and try to find it by its geometry rather than sampling against a given source. The edges of discovered glyphs for instance are jagged, salted with shades of gray (which by the quantity of that could lead to how far the actual line is when blowing up the subject cell in the grid)
One other thing I would do (and I realize how weird it sounds) is to cut up one of your sample texts, identify the grid then produce a totally random other sheet with all characters mixed around. Since your objective is to perfectly identify characters and you’re a human observer, let’s take that humanity down by removing sense in the text and leaving only symbols. Just mix it up and look at it. This excercise (I believe) will force a different human interpretation that can lead to a different or improved algorythm since you’d no longer be able to recognize text patterns and you’d be forced to look at the symbols in isolation.
Ultimately, please forgive me for babbling about on your topic. I tend to challenge and throw grenades and it usually works in changing or adding to perspectives. Including my own. ![]()
It’s common to use a compiler or assembler to check a rekeyed or scanned listing, and if one doesn’t exist then you create a syntax checker from a grammar that describes the type of document you’re working on. The KDF9 operating system project built an assembler to check the listings we rekeyed, and I myself built an Algol 60 syntax checker for algol60 listings that I recovered from OCR’d listings. ( GitHub - gtoal/uparse: Unicode Parser generator. Ordered grammar choices, similar to PEG parsing. Top-down, table-driven, arbitrary lookahead, right-recursive. (Plus demo full algol 60 parser) )
This type of check will find a lot of errors but I can tell you from experience that a small number can still slip through undetected, so reducing the number of errors to begin with is crucial in reducing the number of errors that eventually slip through the cracks.
1 Like