This approach to programming has resurfaced during this year of semi-retirement,spare time and reflection.
My interest in the mechanics of computing have recently been rekindled by the relative ease by which low cost, high speed microcontrollers can be used to simulate classic cpus and systems from past history, or to explore architectures of entirely novel designs.
Ed and his friends over on the anycpu.org forum introduced me to the idea of the “One Page Computer” - which appealed to my desire to keep things simple.
Yesterday I read the paper on the “The Cuneiform Tablets of 2015” - mentioned in a thread some months ago.
The premise of the paper is to successfully preserve our digital archive, for future the benefit of future generations. To leave a time capsule of our digital heritage for future archaeologists to unpack.
I liked the authors approach - stating that the virtual machine description should be able to fit on a one page document - which sounds familiar:
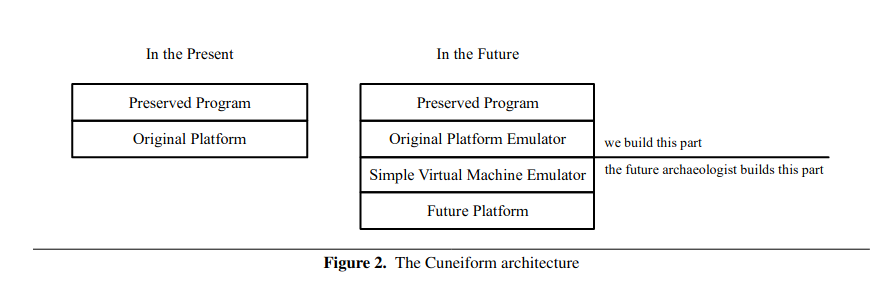
In summary, our “message to the future” should consist of two parts: a “one-page description” of a simple virtual machine, and a program that will run on the simple virtual machine.
Moreover - having acquired the one page document of the machine description, and a sample program, the computer archaeologists of the future should be able to recreate the machine in “a fun afternoon hack”.
Certainly, the series of OPC designs created by Ed, Hoglet and friends, proved that you could rapidly evolve and innovate through a range of different archtectures and instruction sets - implementing each iteration on an FPGA so that relative performance benchmarks could be performed.
The Cuneiform Tablet paper went on to describe a universal virtual machine called Chifir as the basis of their concept.

Some feedback on the discussion thread suggested that this VM might be all very well to recreate the Xerox Alto or Data General Nova, but somewhat sub-optimal for almost any other past or present architecture.
An examination of the instruction set shows that the operands are from memory addressed by registers A, B and C. All operands are taken from the 21 bit memory address space and are 32 bits wide.
The instructions have the full complement of arithmetic operations, but only logical AND, which seems to be a shortfall. Given only 15 instructions, there are perhaps a few that might be more useful.
All arithmetic, logical and comparison instructions are performed on M[B] and M[C] with the result being placed in M[A]. There does not appear to be a means to get a literal value into memory or to initialise the registers to a given value.
With the limitations of the instruction set, and the inefficiency of the architecture, I can’t help thinking that there might be a better approach.
There is a further flaw that I think the Cuneiform Tablet project has - which I will try to illustrate:
Suppose, for example, we assume the roles of the future technology archaeologists and we come across a digital time capsule from 1976. On the disk there is a description of a VM which we implement using our current technology, and a series of example programs that illustrate the capabilities of the original machine, written in the VM code.
In an “afternoon hack” we implement the VM on whatever hardware we happen to have lying around and then load the example programs and experience them in their full glory on a monochrome screen.

For this to work at all, someone back in 1976 would have had to simulate a complete Apple 1 on a virtual machine, transcoding the full 6502 instruction set, implement Apple 1 BASIC and the ascii image itself into a VM bitmap.
However, as future archaeologists we would learn nothing about the workings of 6502, or the Apple 1 or who the guy with the beard was. The archived message that had been put into the time capsule had become so diluted in context that it could easily be overlooked in its significance.
The authors recognised this limitation, and sum it up in this statement:
If the archaeologist of the future wants to modify the emulator or build a hardware replica, she will need to understand how the original platform and its emulator work. For this purpose, we include the source code of the original platform emulator and the compiler for our emulator-writing language.
That’s my take on the Cuneiform Tablet project, a lot of effort but does it really convey an accurate portrayal of our digital archive?