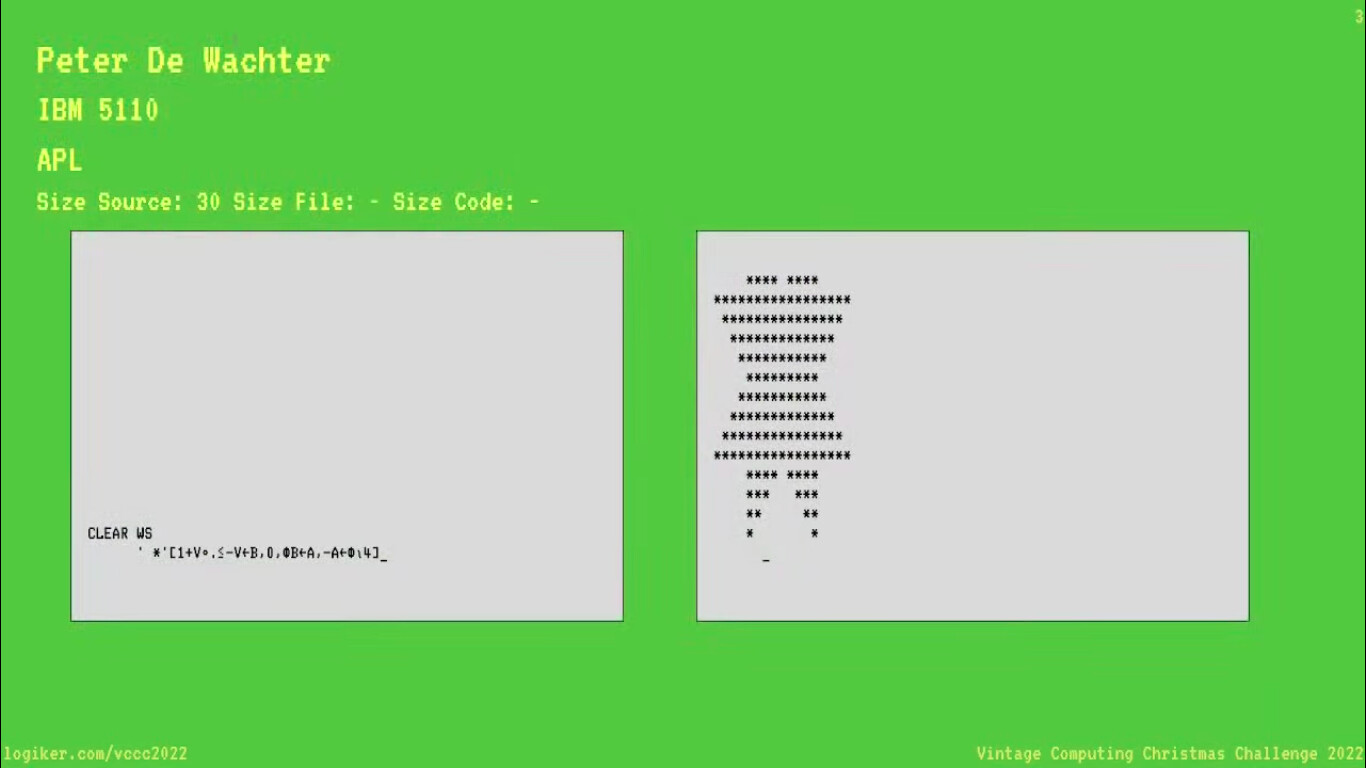
After the 5110 assembly solution, I took a stab at a BASIC solution for the IBM 5110 (not submitted).
Below is the annotated “long” version, to (hopefully) keep the approach straightforward, which is:
- decompose the shape into a few common strings,
- assign those strings to indexes in an array,
- define a data sequence specifying what order to draw the piece-parts strings to reconstruct the desired image.
This is just one of the generic (kind of) “RLE” approaches, whereas the “procedurally (algorithm) generated” approaches should be more efficient (but I suspect more “brittle” at being adaptable to other patterns).
There are some annoying things about this older IBM BASIC on the 5110:
- single line can’t go over 64 characters (can’t wrap to multiple lines on the screen)
- can’t combine commands using colon ‘:’ (you can in certain PRINT statements, but not FOR or IF)
- IF statements can only GOTO (can’t do compound statements, like IF A=5 THEN PRINT ‘5’ is invalid)
- strings consisting of all blanks end up truncated out (had to add keyboard support for the || concatenate symbol to the emulator to test that out)
- arrays starting at index 1 was a typical BASIC thing, right?
200 REM DEFINE 4-CHARACTER PADDING
210 DIM A$4(8)
220 REM DEFINE 1-CHARACTER PADDING
230 DIM B$1(2)
234 REM DEFINE 23-CHARACTER PADDING (FOR CENTERING)
235 DIM C$23(1)
239 REM 8 UNIQUE 'STAR' STRING OPTIONS
240 READ A$(1),A$(2),A$(3),A$(4),A$(5),A$(6),A$(7),A$(8)
248 REM B$ USED FOR SINGLE '*' VS ' ' OPTION
249 REM C$ USED FOR LEFT PAD FOR CENTERING
250 READ B$(1),B$(2),C$(1)
260 READ N
270 FOR I = 1 TO N STEP 5
280 READ A1,A2,B1,A4,A5
290 PRINT C$(1)||A$(A1)||A$(A2)||B$(B1)||A$(A4)||A$(A5)
295 REM || IS CONCATE CODE FOR IBM 5110
300 NEXT I
310 END
400 REM ===========================
405 REM UNIQUE 'STAR' SEQUENCES (GROUPS OF 4)
410 DATA ' '
420 DATA '****'
430 DATA ' ***'
440 DATA ' **'
450 DATA ' *'
460 DATA '* '
470 DATA '** '
480 DATA '*** '
485 REM PLACEHOLDER FOR ON/OFF CENTER PORTION
490 DATA ' '
500 DATA '*'
504 REM BLANK CONTENT (DIM SIZE WILL GET PADDED)
505 DATA ''
510 REM HOW MANY SECTORS (HOW MUCH DATA)
520 DATA 85
530 REM DATA SECTOR ABBREVIATIONS
540 REM A-SERIES INDEXES
550 REM 1=0000
560 REM 2=1111
570 REM 3=0111
580 REM 4=0011
590 REM 5=0001
600 REM 6=1000
610 REM 7=1100
620 REM 8=1110
630 REM B-SERIES INDEXES
640 REM 1=0
650 REM 2=1
660 REM A A B A A
670 DATA 1,6,1,5,1
680 DATA 1,7,1,4,1
690 DATA 1,8,1,3,1
700 DATA 1,2,1,2,1
710 DATA 2,2,2,2,2
720 DATA 3,2,2,2,8
730 DATA 4,2,2,2,7
740 DATA 5,2,2,2,6
760 DATA 1,2,2,2,1
770 DATA 5,2,2,2,6
780 DATA 4,2,2,2,7
790 DATA 3,2,2,2,8
800 DATA 2,2,2,2,2
810 DATA 1,2,1,2,1
820 DATA 1,8,1,3,1
830 DATA 1,7,1,4,1
840 DATA 1,6,1,5,1
Removing all the “fluff” (e.g. REM’s) and streamlining this, I get it down to only 541 bytes. The 5110 had 16KB minimum, but for early vintage systems with only 1-4K, code size really starts to matter. (even with 32K, I realized why many early games didn’t include in-game instructions - English text eats up RAM very quickly).
The IBM 5110 shows the amount of available memory in the bottom right, so it’s easy to monitor on that system. After the first run, then 182 bytes of additional RWS/RAM is used (I assume from the DIM allocations). I’d have to instrument the emulator to see how many instructions the “read” “for” “print” “step” and “next” keyword equate to in the ROM (i.e. to fairly say how much native instruction work is needed to run the BASIC).
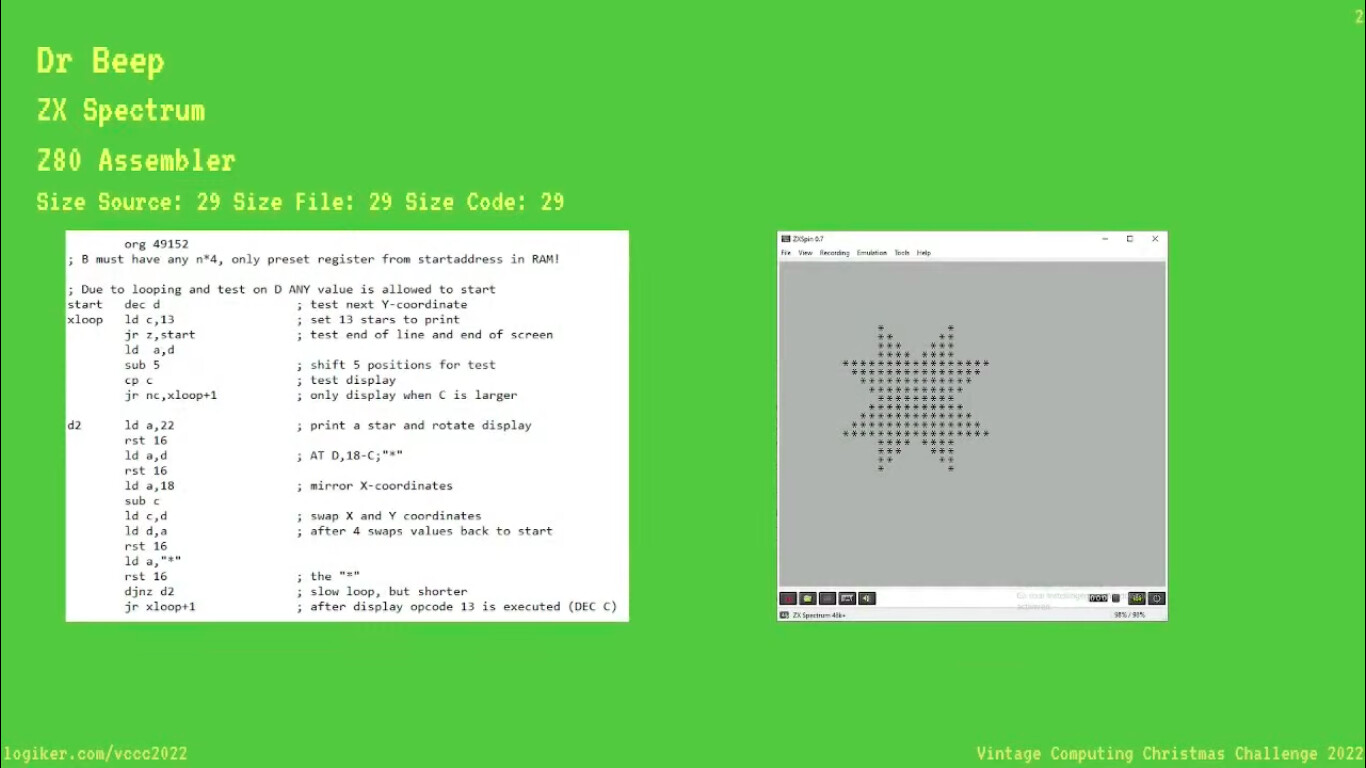
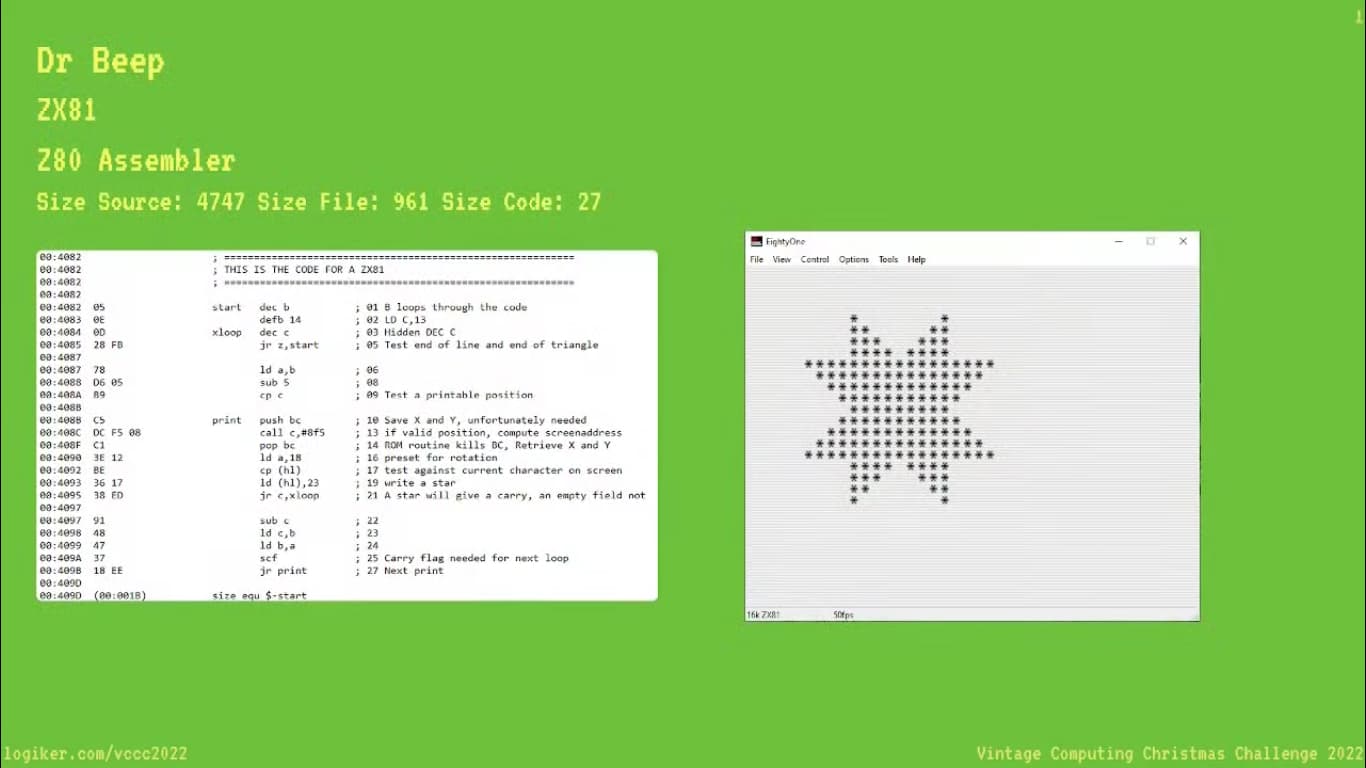
The assembly version is self sufficient but still ~300 bytes - I’d say it was “compiled for speed” rather than size, and had most loops unrolled.