Keeping the old alive: the 731 legacy computing symbols proposed in L2/21-235 were accepted at UTC170 in a new block named “Symbols for Legacy Computing Supplement” for a future version of the standard: since the Unicode 14 was just released, likely the version 15.
Oh, well done! It looks like the Acorn part of the proposal didn’t make it to the final. There’s an oddity in that the 8-bit Acorn community is very healthy and active, in a retrocomputing sort of way, embracing sharing and open source, but the RISC OS (32-bit Acorn) community has a substantial contingent which regard it not as a legacy OS but as a current and future OS, and there’s an emphasis on commercial and proprietary developments.
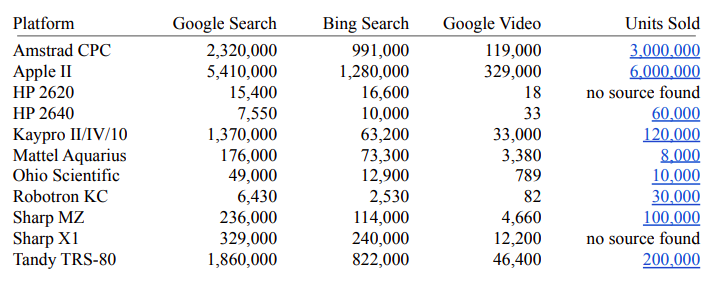
Acorn’s BBC Micro and related 8-bit offerings seem to have sold in the million-plus quantities, whereas their 32-bit offerings (Archimedes and RISC PC) seem to be more in the quarter-million area.
Back in 2012 we posted a font quiz on our G+ mos6502 page:
I think the fourth one is probably Acorn’s 8 Bit font (for the BBC Micro and so on - slightly different from their previous Atom font.)
If anyone from the community would like to see what is not covered already, with pointers to documentation, high-res manual scans, that would be helpful. Note that the allocation from Unicode is not “grabbing contiguous 256 (or 128) blocks for each legacy platform”, but much more complex. For example, font variations or colors are usually not relevant. (But there are exceptions, as I said, complex.) This because Unicode is not a font collection, but data interchange and processing standard.
Also note that the above list of platforms is from the 2021 proposal, not the 2019 one which included the “obvious” ones like C64.
Ah, right, I might have misunderstood: so the RISC OS fonts made the cut previously?
The BBC Microcomputer fonts can be seen in the manual (“BBC Microcomputer System User Guide” as seen here. (Although possibly that’s not quite high enough quality? This one is ever so slightly better.)
Mind that “covered” doesn’t mean 100% coverage, e.g., there are still some PETSCII characters missing.
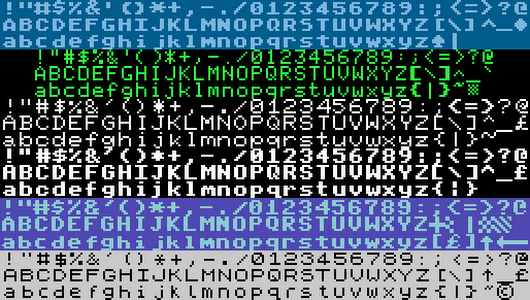
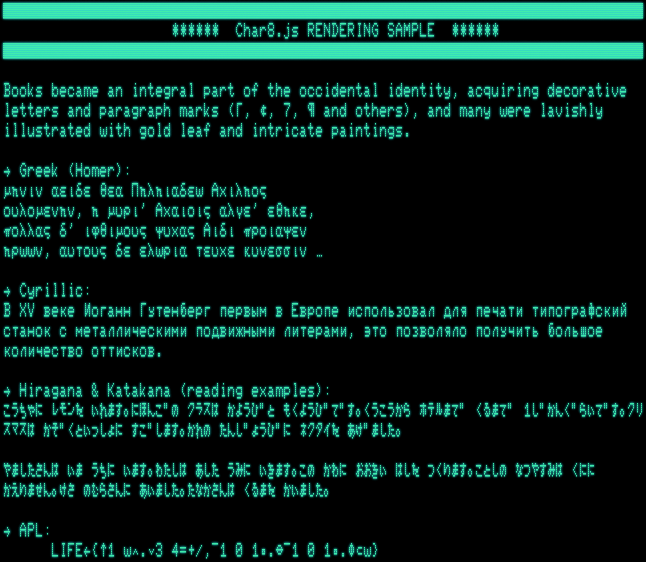
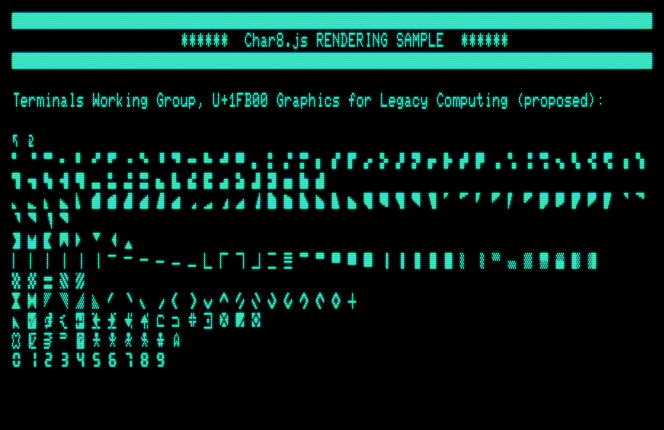
BTW, for 8-bit rendering (in a browser application) compare this JS library, which supplies 8×8 character matrices for Unicode text – with the U+1FB00 range already implemented (as in the proposal):
Great work! I remember charging around my old contacts who worked for Amstrad trying to find names/intents for the last few CPC graphic characters for the previous proposal. We didn’t quite make it in time, sadly.
I know that the official reason given is copyright/IP, but every Subgenius knows that Unicode could never “contain” the image of J.R. ‘Bob’ Dobbs from the Atari character sets
Here are a few examples, the block character ones are from PETSCII, and there are some beloved sprite-characters missing as well (useful to render typical screens):
Regarding “trademark-encumbered”, this would have to be about actual trademarks (much like Taito registered the sprites of Space Invaders), since glyphs are excepted from copyrights (at least in the US and this being still a rather US-centric field), only the implementation can be owned.
(The page is specifically about emojis, but many things apply for outside emojis.)
One thing to note that while Unicode is incorporated in US, it was created and is supported by a multitude of multinational corporations, some of which non-US, so they have to take into account international laws. Therefore, for example, there shall be no Pacman emoji (or legacy character) until Namco will release on its IP regarding the shape of Pacman, allowing it to be freely used. I believe some character sets used to include the AT&T Deathstar: not going to be encoded, and so forth.
What are the codes, 0x??, of these missing ones? If you can list all of them, I can try finding what they map to.
What are the “sprite-characters”? Looking at PETSCII - Wikipedia I see “normal” and “shifted” character sets, and some Internets is using the terms “primary” and “alternate”, but neither of them has these game graphics?
Also note that many “unusual” characters have been coded already years ago, outside this “legacy characters” effort, for some other reason, for example coming from some other set. So if one does not see their character in these legacy sets, that does not mean that they are not already encoded. For example, looking at that PETSCII Wikipedia page, the upper-right circle quadrant has Unicode 256E which means it was encoded long time ago, since the legacy set is e.g. 1FB7F
The “still no 8x8” ones are
0xB7, 0xB8 and 0xB3, 0xB4
The problem here is that Unicode has directional “Eight Blocks” and requires negative print for some of the required block elements are not available in normal print. The new range adds to these, but quite a portion is sextant based (like Prestel/video text). This may not be so much of a problem with C64 “fat characters”, but may be observed with the original PETSCII as seen on the PET. See the top of <Now Go Bang!> PETSCII Revealed for my attempt to match a screen rendition to the currently available Unicode ranges.
It becomes even more apparent, if you try to convert abitrary screens. (E.g., play around with https://www.masswerk.at/pet/ and get a Unicode representation using the context menu of the screen and select “Export Screen as Text” or “Copy as Text”. – Especially from games, see the “Prg Library” for some popular games, e.g., “Miner”.)
As for “sprite characters”, these are figurative characters for use in games, like space ships, human representations in various orientations, etc (see “Some things nice to have” in the above image.) The new range adds some of these, but misses others on popular platforms (again, see the above image.)
Where would be a good place where these are documented for PETSCII? Are they like an “alternate character set” that can be accessed with some appropriate POKE?
I’ll have closer look at the current state of affairs in the next days. It may be better to wait for this, as I could then provide a definitev statement.
That’s the idea. I want to render the original glayphs from ROM and the various mappings side by side to get an idea. Might be also interesting, where and how these differ from another.
However, one thing still missing from Unicode is a modifier to render negative text, AKA reverse video (i.e. print a filled em-square with the glyph outlines as conters/transparent text).
A general solution could be a combining mask-modifier followed by a filled em-square for the reverse background . E.g., “A<MASK><FULL BLOCK>” for an “A” in reverse video (similar to U+1F170, “NEGATIVE SQUARED LATIN CAPITAL LETTER A”), where the modifier would also center the masking glyph on the following character. There’s a huge potential for misuse, though.