Maybe Niklaus Wirth’s Compilerbau (Compiler Construction). I’m actually not sure about the date, as the preface is signed 1979, but my German edition comes with a copyright of 1986, and the English edition points to 1996. Notably, the book has been constantly revised (starting with the third edition it switches to Modula II as the host language). However, it just covers the basics and the idea of incremental compilation, featuring the famous T-grams (update: apparently not in the English edition). – Not exhaustive, but an important book.
For Algol, this is a bit systematic as no discription covers the implementation of libraries, as far as I know. But this also spills over to derived languages, like Simula67, where there is no description of how this is actually implemented (there is just writting to buffers and a routine to flush said buffers, but that’s basically it). Arguably, Simula67 never reached that level of implementational refinement that it would matter…
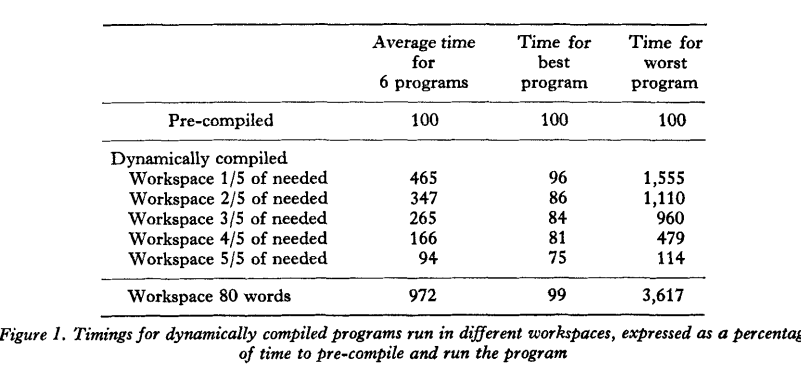
we compiled things like fortran, Basic plus 2, etc in 16K user space on PDP-11’s
Symbol tables can be written to and read from disk during the process.
Now what computer compiled at 1 card per minute again?
Slow compile times was because of the lack of real memory, disc space,
and slow OS’s. Virtual memory was just that, slow but big.
This may of pushed the development of one pass compilers (C is two pass+)
but that just made things much slower at run time, like pascal.
Wirth likes to revise a new language every few years,why not do it right
the 2nd time, PASCAL or MODULA II, or ADA all gone now for OBERN.
I really think a complier is better multipass, parsing and error checking on pass number 1.real compiling pass 2. Nobody seemed to want to create a easy to compile language
and no wierd ; rules, like a null statement or no ; before a end.
The 80’s things got better, when you had ample memory for things like compiling.
After that everybody went to 32 bit cpu’s, and langauge development stopped
as changing CPU’s was the FAD for a while. 286, now 68000,now 486, now RISC,
now 586, divide bug now other brands, now ARM, now DEC’s RISC, now the CHEAP
686…
As a side note. I don’t like revised editions. it needs to be a new title for major changes.
The real rule for ;'s is statement | statement ‘;’ statement
nowhere does it end or terminate a statement.
I’m not clear on how compiling could save memory compared to interpreting. Is the source code not stored in RAM? Maybe makes sense of they come with discs or something.
Depending on the format of the compiled code, it may be possible to de-compile it to get back something equivalent (maybe even identical) to the original source code.
If you want to see this in action, you can go to this (online) PET emulator and type some lines of BASIC. Then, by selecting “Disassemble Program” from the “Utils / Export” menu (below the emulated screen), you can see how this is stored in memory.
The compilation on the NewBrain exceeds this usual tokenization significantly, and – as mentioned by @ellvis – the program is actually stored twice, once as the original source code, and once as a compiled version as the program ist executed.
(So it uses more memory, but should benefit from the compiled version in terms of speed, if a line is executed more than once. If the computer runs low on memory, some of the stored compiled code may be purged again – and will have to be recompiled, if the respective lines are executed again.)
Well that’s not strictly true - it does use ASCII it just doesn’t have all that extra ROM code to parse, tokenise and what not as it has the ability to type the token values directly into the program.
This isn’t unique - I remember doing it with BASIC on the Atari 2600 back then too and I’m sure there were several others with a similar single key per keyword entry system too.
It has a lot going for it too - no parsing and tokenising code in the ROM and quicker to type once you learned where all the keywords were but I remember using them and initially being frustrated as delete would delete the whole keyword, so if you didn’t look you might delete too much…
On a more serious note, the Sinclair computers were notable for their modal editor / line input. This is why the cursor is an inverse letter, indicating the mode of the expected input. Were there any other computers that did this (maybe even some prior art)?
Just to clarify… I didn’t write that program on the 2600 - it was a BASIC cartridge that used 2 x 12-key handsets that allowed you to write BASIC on the 2600. Brave in many aspects though - a 4-way shift key to select keywords etc. in under 100 bytes of code and data space.
No, this improves the performance of the parser. Atari BASIC did the same.
The idea is that you enter the parser in a “initial state” so as you parse the source you are only looking for items in the “first list”. So this would contain both ? and PRINT, as well as INPUT and LET and anything else that appears at the start of a line, “statement keywords” or some variation on that term. Once you have found the keyword, you set a flag that says you are no longer in the initial state, and from then on you look through the second list.
There are a couple of advantages, but I can’t say which is the most important:
The lists are shorter so the search time improves. This is not going to be huge because you probably sorted the lists on popularity. But then…
You can sort the two lists separately, which likely does have some impact. PRINT and + can both be at the top of their respective lists. Again though, this is at edit time so it will not have a huge overall impact.
You have more room. Since the initial token in a statement must come from the first list, you don’t need to have the high bit set to indicate its a token. Contrast this with MS, where the first item can be a variable name, so they have to have the high bit on all their tokens to make this easy. This means you can use 255 tokens in the first table and 128 in the second which gives you lots more room to work in. But on the flip side, the first list often ends up being quite short.
There’s really no downside. You have to have a bit somewhere to say what part you’re parsing, and you need to check it every time, but in the grand scheme this is a triviality and one that is at edit time in these BASICs.
I suspect the reason for this is that most BASIC programs only touch a subset of their lines during a typical run. Depends on the program, of course, but I suspect something like Super Star Trek only hits about 2/3rds of its lines for any given game. So doing a lazy compile makes sense in these situations.
It should also help with dealing with low memory conditions. Just purge some object code memory and reset the code pointer for the related lines to zero, and you’re ready to compile and store the line you’re currently dealing with. (The overhead souldn’t be significant. I think, this is really clever.)
I hadn’t heard of any except the Jupiter Ace before this thread. I did like the idea of a built in high level / beginners language with a bit more performance, so you could write games more like the machine code games I liked playing.
The modern retro colour maximize 2 and picomite achieve this by having a much faster processor. (Probably similar with BBC basic for raspberry pi pico/VGA, though I haven’t used that)
A bit of a diversion perhaps, but I’ve just stumbled on the 17 page paper A Brief History of Just-In-Time by John Aycock (via) which mentions several interesting early experiments and developments, including a pointer to Brown’s 1976 paper Throw-Away Compiling. Brown writes a Basic interpreter/compiler in Pascal for a CDC 6400 (“neither was the ideal choice”) and takes timings of various space allocations. With minimum allocation the thing works rather like an interpreter, with maximal allocation it performs rather like a compiler.
Also worth mentioning in the context of early JIT compilers: Dan Edwards’ outline compiler for the spaceships in Spacewar! (early 1962). This was an optimization of a previously interpreted tiny graphics language, which was now compiled to machine language. Notably, Dan Edwards also devised the garbage collector, on which Steve Russell’s implementation of LISP relied on. (Steve Russell was not only the first to implement LISP as a real language and doing away with M-expressions, but also Spacewar’s main author.)
(This tiny graphics language consisted of 5 directional move-and-plot commands, 1 position store/restore toggle command, and 1 mirror-and-redo/end command. It uses a pre-processed matrix to advance along a main axis in its current orientation in 2D space, storage for the main coordinates and an extra pair to store one X/Y position, and a couple of flags for the main control flow, as two of the commands are contextual.)
Fun fact: Since early implementations of Spacewar had to be re-run manually for a new game (automatic program restart was added only later), the outline compiler runs at the start of each game, even in matchplay mode, where players compete over a preset number of games.
Fun fact 2: As this was quite an extensive optimization along the time vs space paradigm, Spacewar! has a special configuration variable to display both players’ ships by the same outline (while normally displayed as individual shapes), in order to reserve space for the “dtd” online-debugger (the first software debugging device). There’s no JIT without trade-offs…