I saw a question in another Internet forum earlier that reminded me of a very interesting (to me) piece of computing history. The original Apollo workstation ran on a Motorola 68000 processor, which had a design flaw that prevented page fault instructions from being properly interruptable and restartable, making “safe” memory management with non-error page faults difficult. A proposed fix from Motorola was to install a second 68000 processor just to handle page faults and correct this error, so that the primary processor’s bus cycle can be restarted (after signaling a bus error). I had heard of this trick a number of times over the years (although it was sometimes characterized as being used in the Sun 1, which also used the MC68k processor; perhaps it also used this technique, I don’t know, but it used a custom MMU so perhaps it was not necessary), but never chased it down and confirmed it as not-an-urban-legend.
It turns out that it is definitively not! Motorola issued a document, Design Concept DC-001: Virtual Memory Using the MC68000 and the MC68451 MMU, that describes the workaround that I believe was implemented on the Apollo, which is available for examination.
The first proposal outlined in the documentation is described as “relatively conservative of hardware”, which seems like a surprising characterization to me, given that it involves installing a second state-of-the art and quite expensive CPU! A block diagram for this “bus rerun” architecture is presented, with the caveat that read-modify-write instructions like test-and-set cannot be restarted, and so user software that may invoke this page fault mechanism cannot use such instructions.
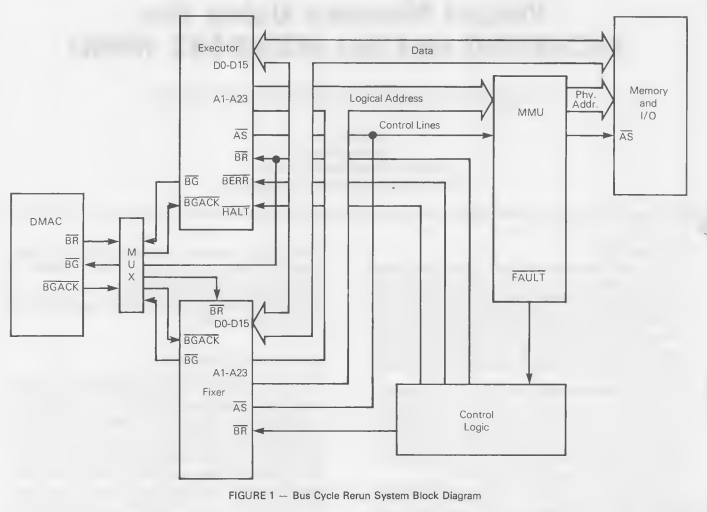
Note that both the blocks labeled “Executor” and “Fixer” are 68000 microprocessors in this diagram, while the block labeled “MMU” is a 68451.
The application note goes on to describe a “bus cycle suspension” method that, instead of restarting the bus cycle after correcting the fault, inserts wait states on the primary CPU while the fault is corrected, allowing it to continue (rather than restart) its interrupted bus cycle. This method, while superior to the “bus rerun” method in that it has no limitations on what instructions can be subject to page faults and still complete successfully, is said to have the disadvantage of “the amount of hardware required”. Nonetheless, the note (correctly, in my opinion) asserts that this method is “preferred as it results in a more powerful and versatile system.”
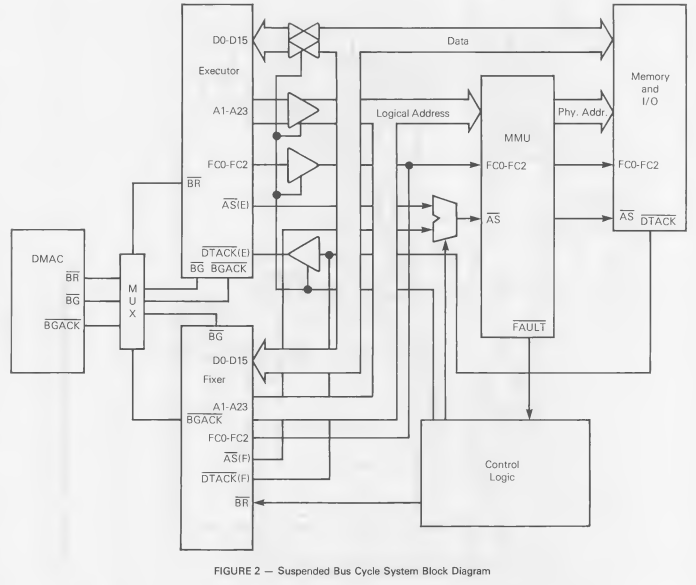
The document goes on to provide a full schematic for the suspended bus cycle method, as well as various timing diagrams and functional descriptions to help an implementer make this dream (nightmare?) a reality.
I do not know which method the Apollo workstation in question used, but I suspect it was the second – documentation can probably found to confirm this, but I have not personally checked. As Wikipedia notes, the Motorola 68010 fixed this deficiency, and did not require the workaround.